Artificial Intelligence has become inseparable from modern software development. Today, developers don’t just use LLMs for novelty, they rely on them to debug CI/CD pipelines, refactor massive repositories, or even act as coding copilots inside IDEs. The shift is clear: choosing the right LLM is now as important as choosing the right framework or database.
But here’s the problem: the LLM ecosystem in 2025 is crowded. Anthropic, Google, xAI, and open-source players like Qwen and DeepSeek are all competing for developer trust. Each claims to be faster, cheaper, or more accurate and depending on your use case, they might all be right.
So how do you decide which one actually fits your workflow?
This guide brings together real-world adoption data (from OpenRouter and Kilo Code leaderboards) with hands-on developer analysis. It doesn’t just show you which LLMs are popular it explains why developers are choosing them, what tasks they excel at, and how you can evaluate them yourself.
By the end, you’ll know how to build your own LLM strategy whether you’re an indie hacker, a startup engineer, or part of a large enterprise team.
LLM Usage Trends in 2025: Who’s Winning the Adoption Race?
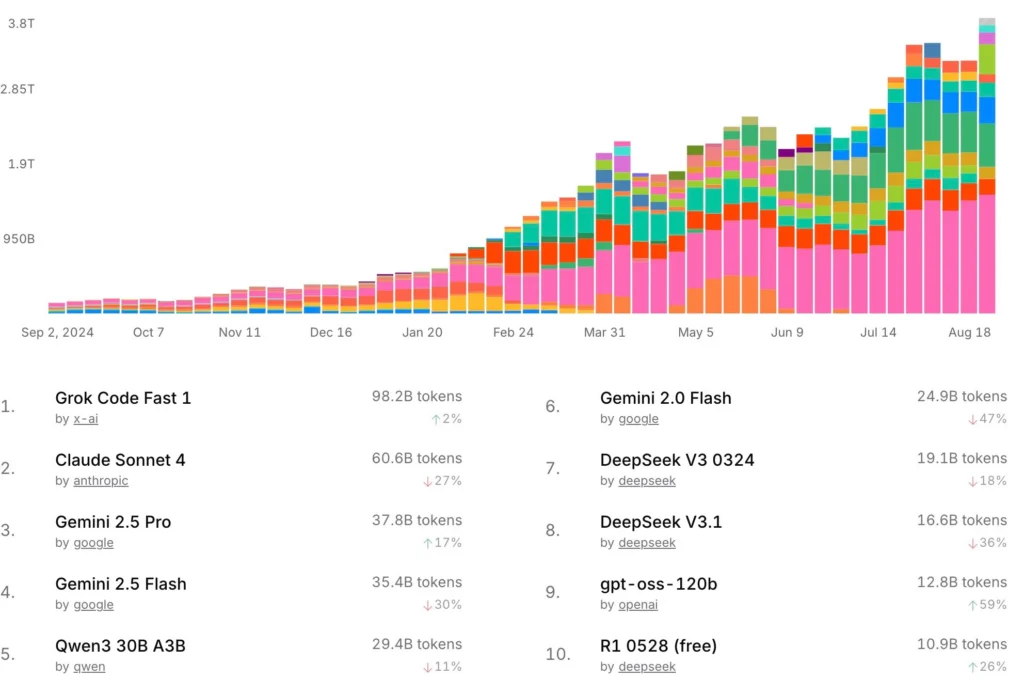
When it comes to developer tools, adoption tells the real story. Benchmarks are useful, but what developers actually use in production is more revealing. Leaderboards from OpenRouter and Kilo Code (a VSCode-integrated AI agent) highlight some clear trends:
- Claude Sonnet 4 (Anthropic) dominates in tokens consumed. Enterprises trust it for precision and safety.
- Grok Code Fast 1 (xAI) is a breakout star. Despite being new, it’s already in the top 3 models across multiple charts.
- Gemini 2.5 Flash and 2.0 Flash (Google) remain stable, popular for their speed and versatility.
- DeepSeek V3.1 and V3 0324 show explosive growth, with usage increasing 171% and 118% in a single month.
- Qwen3 models (480B, 30B A3B) are climbing steadily, especially among open-source-friendly devs.
- GLM 4.5 Air and Horizon Beta are smaller but notable contenders.
- GPT-5 is still relevant but no longer the “default choice” for developers.
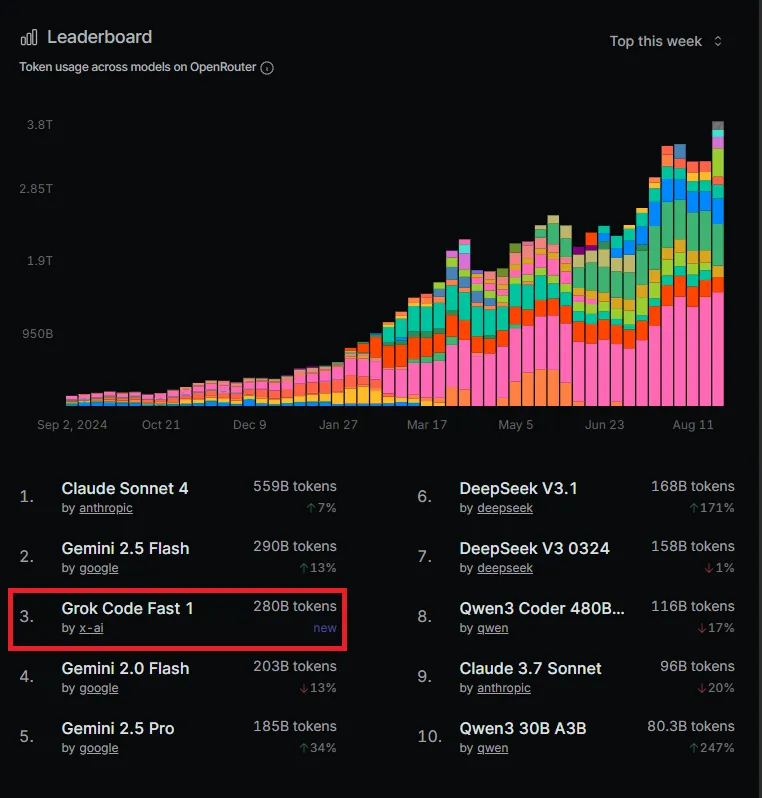
The real story isn’t just about leaders. It’s about momentum. Claude holds its ground, but Grok, DeepSeek, and Qwen are rising fast, powered by affordability, developer-first tuning, and integration into workflows like VSCode and CI/CD pipelines.
What Makes a Coding LLM Different From a General LLM?
General-purpose LLMs like ChatGPT or Perplexity are good at answering questions or generating text. But coding-optimized LLMs are tuned for different priorities.
- Instruction discipline. Developers need precision. If you ask for a function rename, you don’t want the model rewriting unrelated code.
- Large context handling. Codebases are big. A strong coding LLM can process millions of tokens so it understands dependencies across multiple files.
- Testable outputs. Code either runs or it doesn’t. Coding models are evaluated on pass/fail rates, not just fluency.
- Workflow integration. The best LLMs plug directly into IDEs, CI/CD systems, and agents, making them part of the development loop.
This is why models like Claude Sonnet 4 or Grok Code Fast 1 feel different in practice than GPT-style assistants. They don’t just talk about code, they work with it.
How We Compare Coding LLMs
For this playbook, every model is judged on some criteria that matter most to developers:
- Speed (latency and throughput): How quickly can it return usable results?
- Cost: How affordable is it per request or per coding task?
- Context window: How much code or documentation can it process at once?
- Instruction following: Does it stick to your exact instructions?
- Tool use: Can it call functions, execute snippets, or analyze multimodal inputs?
These aren’t just benchmarks. They reflect what developers feel every day in their workflows.
| Model | Best At | Speed | Cost | Context Window | Instruction Following | Tool & Multimodal Support |
|---|---|---|---|---|---|---|
| Claude Sonnet 4 (Anthropic) | Precision refactors, enterprise reliability | Fast but deliberate | $$$ Premium | 1M tokens | Strictest | Extended reasoning, safe tool use |
| Gemini 2.5 Flash (Google) | Versatility, multimodal debugging | Very fast | $$ Mid-tier | 1M tokens | Strong but sometimes creative | Function calling, code execution, multimodal inputs |
| Gemini 2.0 Flash (Google) | Cost-effective scaling | Very fast | $ Cheapest | 1M tokens | Solid, less strict | Basic tool use, reliable bulk generation |
| Grok Code Fast 1 (xAI) | Fastest interactive coding loops | Fastest | $ Low | 256K tokens | Good, less strict | Optimized for IDEs & CI/CD |
| DeepSeek V3.1 / V3 0324 | Affordable code-focused performance | Fast | $ Very low | 128K–256K tokens | Decent, improving | Lightweight, open-friendly |
| Qwen3 (480B / 30B A3B) | Open-source customization | Moderate | $ Low | 128K–256K tokens | Flexible | Open weights, self-hosting possible |
| GLM 4.5 Air | Lightweight deployment | Moderate | $ Low | Smaller contexts | Fair | Efficient inference, niche use cases |
| Horizon Beta | Experimental testing ground | Moderate | Variable | Medium contexts | Developing | Early-stage tool support |
| GPT-5 (OpenAI) | General-purpose versatility | Fast | $$$ Premium | 1M tokens | Strong but not coding-specialized | Mature tool ecosystem, but not code-optimized |
Claude Sonnet 4: The Precision Refactorer
Claude Sonnet 4 is Anthropic’s flagship and the safest bet for enterprise-grade accuracy. It handles 1M-token context windows, making it possible to pass entire repositories or multi-thousand-line logs. Unlike Grok or Gemini, Claude is extremely strict in following instructions: if you ask for a rename, it will only rename, no creative drift, no extra comments.
Developers evaluating Claude often ask: “Can I trust this model to only do what I tell it to?” The biggest risk in large repos is when an LLM decides to “improve” unrelated code. That’s why we use a refactor example — it demonstrates Claude’s strict instruction-following, so you can see why it’s safest for production refactors.
# Before
def process_payment(user, amount):
validate_user(user)
deduct_balance(user, amount)
# After (Claude)
def handle_payment(user, amount):
validate_user(user)
deduct_balance(user, amount)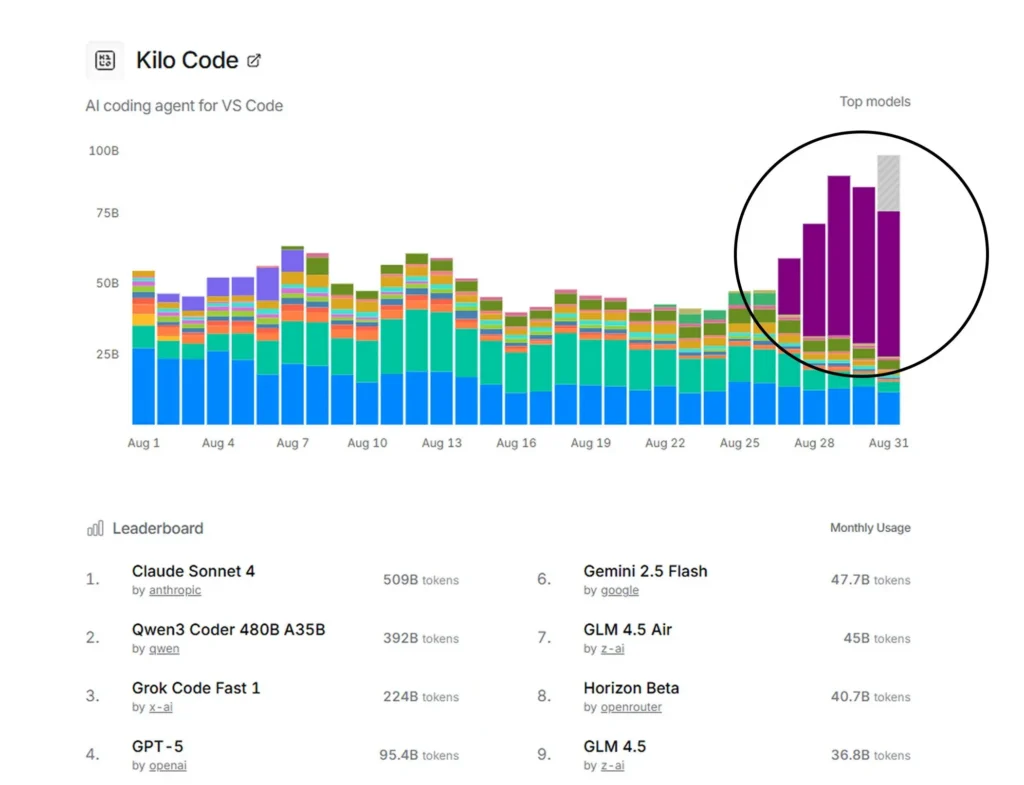
Why Developers Choose Claude
- Enterprise safety: Enterprises love Claude because a single stray edit could break critical systems. Claude minimizes that risk.
- Context mastery: Its 1M-token context window makes it possible to pass in whole repositories or logs spanning hundreds of files.
- Extended reasoning: Claude can handle deep debugging tasks where logical analysis is as important as code edits.
Trade-offs
- Cost: Claude is significantly more expensive than Grok or Gemini 2.0.
- Speed: It’s fast, but not designed for instant edit-test loops. Developers sometimes describe it as “deliberate” rather than snappy.
Best Fits
- Enterprise teams in finance, healthcare, or infrastructure.
- Refactors spanning dozens of files.
- Debugging complex dependencies where safety outweighs cost.
Gemini 2.5 Flash: The Versatile Multimodal Workhorse
Gemini 2.5 Flash is Google’s “Swiss Army knife.” It combines 1M-token context with multimodal capabilities (logs, screenshots, diagrams). It supports function calling, tool integration, and code execution, making it ideal for debugging across messy environments.
Gemini stands out for its multimodal debugging: combining logs, error messages, and even screenshots. The example here uses a common Java error (NullPointerException) to show how Gemini can read logs and suggest fixes. This illustrates why you’d choose Gemini if your workflows involve diagnosing production issues beyond pure code generation.
Example: Debugging with Logs and Screenshots
A developer provides both:
- Log snippet:
Error: NullPointerException in OrderService.java at line 42- Screenshot of the server dashboard showing memory spikes.
Gemini 2.5 Flash output:
- Root cause:
getOrderDetails()returned null becauseorderIdwas missing. - Secondary note: memory spike caused by retries on null pointer.
- Fix: add
if orderId is None: raise ValueError("OrderId required").
This combination of text + visual context makes Gemini stand out for debugging production issues.
Why Developers Choose Gemini 2.5
- Balanced speed and reasoning: Fast enough for interactive loops, smart enough for complex analysis.
- Multimodal support: Perfect for scenarios where data isn’t purely textual (e.g., screenshots of error dashboards).
- Tool use: Function calling and code execution extend it into agent workflows.
Trade-offs
- Cost: more expensive than Gemini 2.0 Flash, cheaper than Claude.
- Instruction drift: Sometimes Gemini “gets creative” and goes beyond strict instruction, great for exploration, risky for precise edits.
Best Fits
- Debugging in production where logs, screenshots, and text need to be analyzed together.
- Agent workflows (Gemini plays well in tool-using environments).
- Best for startups and enterprises needing a versatile model for coding and research.
Grok Code Fast 1: The Speed Demon
Built by xAI, Grok Code Fast 1 is optimized for raw speed. It’s the fastest in interactive coding tasks, and its low cost makes it attractive for indie devs and startups. With 256K tokens, it can’t process whole repos like Claude or Gemini, but its responsiveness is unmatched.
The main selling point of Grok is speed. Developers want to know: “How fast can I fix a failing test or patch a bug?” That’s why this example uses a simple unit test correction, it shows Grok’s ability to handle quick edit–test–edit loops, which is why it feels instant inside an IDE.
Example: Interactive Test Loop
# Original failing test
def test_discount():
cart = Cart(items=[Item("Book", 100)])
assert cart.total_with_discount(0.1) == 80 # wrong expectation
# Grok Code Fast 1 fix
def test_discount():
cart = Cart(items=[Item("Book", 100)])
assert cart.total_with_discount(0.1) == 90
The magic isn’t the sophistication, it’s the speed. In edit → test → edit workflows, Grok feels almost instantaneous, making it perfect for hackathons and CI/CD pipelines.
Why Developers Choose Grok
- Speed: Fastest real-world model in coding tasks.
- Cost: Affordable compared to Claude or Gemini Pro.
- Agent-optimized: Works seamlessly in IDE plugins like Cursor or VSCode extensions.
Trade-offs
- Context window: 256K tokens, enough for most mid-sized repos, but smaller than Claude or Gemini’s 1M.
- Narrower skillset: Excellent at code edits, weaker at research-heavy or non-coding tasks.
Best Fits
- Indie hackers iterating on prototypes.
- Startups optimizing for speed and cost.
- CI/CD pipelines where turnaround time is crucial.
Gemini 2.0 Flash: The Budget Workhorse
Gemini 2.0 Flash doesn’t try to be everything it aims to be cheap, fast, and reliable. For teams running thousands of requests a day, that’s a game-changer.
Gemini 2.0 is about cost efficiency at scale. The code example uses bulk unit test generation — not glamorous, but something teams need thousands of times over. This shows why Gemini 2.0 is the go-to when cost-per-request is the main decision factor.
Example: Bulk Unit Test Generation
# Input function
def is_even(n: int) -> bool:
return n % 2 == 0
# Gemini 2.0 Flash output
def test_is_even_positive():
assert is_even(4) == True
def test_is_even_negative():
assert is_even(5) == False
def test_is_even_zero():
assert is_even(0) == True
Gemini 2.0 generates thousands of tests cheaply, saving time and budget.
Why Developers Choose Gemini 2.0
- Cost: Cheapest mainstream model with 1M context.
- Scaling: Perfect for high-volume workloads (developer bots, test suites).
- Speed: Very fast, even for bulk jobs.
Trade-offs
- Reasoning depth: Not as strong as Claude or Gemini 2.5.
- Reliability: May require retries on complex tasks.
Best Fits
- Developer Q&A bots.
- Bulk test generation.
- Large-scale assistants where cost savings matter most.
Rising Stars: DeepSeek and Qwen
DeepSeek V3.1 and V3 0324
The fastest-growing models of 2025. Adoption grew by 171% and 118% in one month. Developers choose DeepSeek for its low cost and efficient performance.
- V3.1 is tuned for interactive coding tasks.
- V3 0324 is optimized for production workloads.
Winning on price-performance, not yet rivaling Claude or Gemini in features.
Best for: Cost-conscious teams, open-source-friendly workflows, early adopters.
Qwen3 (480B and 30B A3B)
Alibaba’s Qwen models are gaining traction fast. Open, customizable, and self-hostable.
- Qwen3 480B: heavyweight reasoning for enterprise-scale tasks.
- Qwen3 30B A3B: efficient mid-range option, good balance of performance and cost.
Best for teams that want control and openness over closed APIs.
GLM 4.5 Air, Horizon Beta, and GPT-5
- GLM 4.5 Air: Lightweight, optimized for inference speed in niche coding use cases.
- Horizon Beta: experimental, growing slowly, watched closely.
- GPT-5: widely used for general tasks, less favored for pure coding compared to specialized models.
How to Integrate LLMs Into Developer Workflows
The best LLM is the one that fits where you code. Here’s how developers are integrating them:
- IDE (VSCode, Cursor): Grok Code Fast 1 for instant loops.
- CI/CD pipelines: Grok for speed, Claude for precision patches.
- Developer bots: Gemini 2.0 Flash for high-volume queries.
- Agent workflows: Gemini 2.5 Flash for planning + tool use.
- Open-source stacks: Qwen or DeepSeek for teams needing self-hosting.
This hybrid approach mirrors real usage no one model does it all.
How to Benchmark LLMs Yourself
Specs are marketing. What matters is how a model performs on your codebase. That’s why building an evaluation harness is critical.
Steps:
- Collect coding tasks (bug fixes, refactors, test gen).
- Run them through each LLM.
- Measure:
- Accuracy
- Latency
- Cost
- Reliability
Pseudo-code Harness
tasks = [bug_fix1, bug_fix2, refactor1]
models = [claude, gemini25, grok, deepseek]
for task in tasks:
for model in models:
result = model.solve(task)
log_metrics(model, task, result)
Evidence-based clarity instead of opinions.
Future Outlook: What’s Next for Coding LLMs?
The next 12 months will reshape the ecosystem:
- Pricing wars will drive per-token costs even lower.
- Context windows will expand past 1M tokens.
- Agent-native design will become the standard.
- Open-source challengers like Qwen and DeepSeek will grow faster than incumbents.
Developers have more options, lower costs, and better workflows.
Conclusion
Claude remains the precision leader. Gemini balances versatility. Grok defines speed. DeepSeek and Qwen represent the rising open-source wave.
The lesson? Stop thinking in terms of “the best model.” Instead, think of LLMs as a toolbox. Pick the right tool for the right job:
- Claude for sensitive edits.
- Grok for IDE loops.
- Gemini Flash for bulk tasks and multimodal debugging.
- Qwen and DeepSeek for open-source customization.
This hybrid approach gives you speed, cost savings, and precision without being locked into one vendor. The future of coding isn’t one model. It’s all of them, working together.
FAQs
The fastest in practice is Grok Code Fast 1. It was designed for interactive edit → test → edit loops and consistently feels instant inside IDEs like VSCode. Developers use it heavily in CI/CD pipelines and rapid prototyping, where every second counts.
Gemini 2.0 Flash is the most affordable mainstream option, combining a 1M-token context window with the lowest per-request cost. For teams building developer bots or bulk test generators, this makes it the best choice.
Runners-up: DeepSeek V3.1 and V3 0324, which are seeing explosive adoption thanks to their low-cost performance balance.
Claude Sonnet 4 leads here. Its strict instruction ensures it only makes the changes you ask for. For sensitive enterprise codebases, this discipline reduces the risk of breaking unrelated parts of the system.
Gemini 2.5 Flash is the most versatile multimodal model. It can analyze text, logs, and images in the same session, making it ideal for debugging real-world production issues.
Yes. Open-source models like Qwen3 and GLM 4.5 Air can be self-hosted. These are popular in organizations that require on-premise AI to meet compliance requirements. The trade-off is infrastructure overhead compared to cloud-hosted proprietary models.
No. LLMs are best at augmenting workflows: generating code, fixing bugs, or analyzing logs. System design, architecture, and nuanced problem-solving require human developers. Think of them as co-pilots that accelerate your work.
DeepSeek V3.1 and V3 0324 (+171% and +118% adoption).
Grok Code Fast 1, which shot into the top 3 leaderboard within weeks of launch.
Qwen3 series, gaining traction as open-source-friendly models.