Google has taken a decisive step toward the future of autonomous digital agents with the launch of its Gemini 2.5 Computer Use model, now available in public preview through the Gemini API, Google AI Studio, and Vertex AI.
The release introduces a specialized extension of Gemini 2.5 Pro, designed to power agents that can interact directly with graphical user interfaces clicking, typing, scrolling, and navigating web environments just like humans do. While the recently introduced Nano Banana image model showcases Gemini’s creative potential in visual generation, the Computer Use model extends that same multimodal intelligence toward real-world interface interaction.
Alongside this, Google has unveiled a newly redesigned AI Studio experience, creating a cohesive environment for developers to build, test, and deploy agentic applications faster than ever.
Gemini 2.5 Computer Use Model Features and Capabilities
Traditional language models interact with software through structured APIs. Yet many real-world digital tasks like filling forms, toggling dropdowns, or submitting entries, still happen in GUIs not exposed by APIs. The Gemini 2.5 Computer Use model bridges that gap.
Built on Gemini 2.5 Pro’s visual understanding and reasoning stack, this new variant can perceive a live interface, interpret layout elements, and decide what actions to take next. It effectively acts as an intelligent browser operator capable of performing multi-step tasks across websites and apps.
Google reports that it outperforms leading alternatives on multiple web and mobile control benchmarks, including Online-Mind2Web (Browserbase), all while maintaining lower latency and higher accuracy.
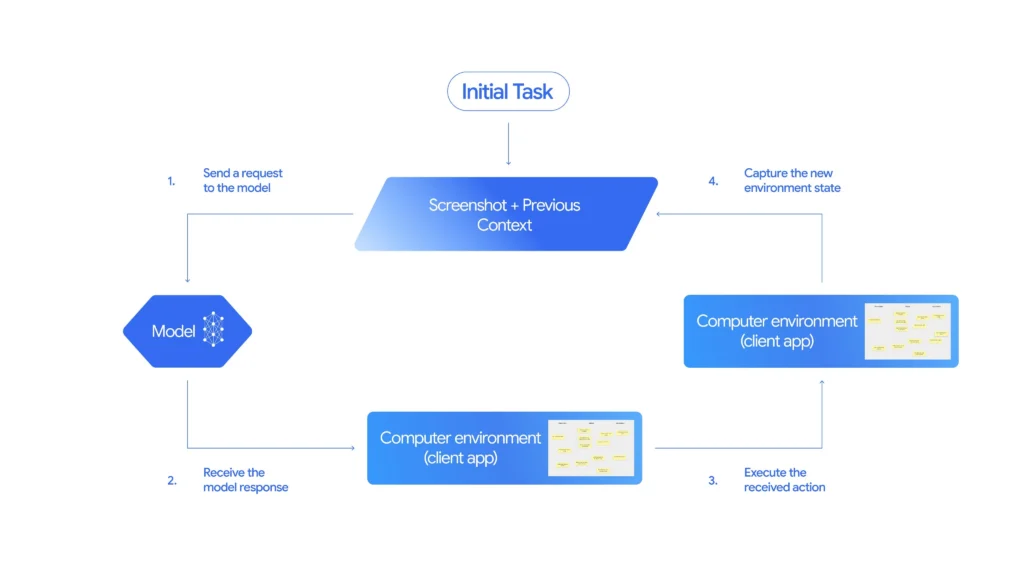
How the Gemini Computer Use API Loop Works
At the core of this capability is a new tool in the Gemini API called computer_use.
Developers invoke it within a continuous action–feedback loop:
- Input Phase:
The model receives:- A user request (what to accomplish)
- A screenshot of the current environment
- A history of recent actions
- Reasoning & Action Generation:
The model analyzes the screenshot and state context, then outputs a function call such asclick,type,scroll, orconfirm.
For higher-risk steps like purchases the model explicitly requests user confirmation. - Execution & Iteration:
The client executes the proposed action and returns a new screenshot and URL back to the model.
The process repeats until the task is completed, an error is encountered, or the model halts for safety reasons.
This closed-loop architecture allows the system to autonomously adapt to dynamic interfaces a fundamental step toward reliable, general-purpose AI agents.
Real-World Gemini Computer Use Applications and Demos
In public demos, Google showcased the model’s dexterity through complex multi-site workflows:
- Pet Spa CRM Automation: From a pet-care signup form, the model collected customer details, added them to a CRM, and scheduled an appointment all by navigating real webpages.
- Collaborative Board Organization: In another demo, it cleaned and rearranged digital sticky notes across categories on a cluttered whiteboard app, executing precise drag-and-drop actions.
These examples highlight how agents can now manipulate unstructured digital environments as naturally as humans, without pre-built API connectors.
Example Prompts for Gemini 2.5 Computer Use Model
To illustrate real-world usage, Google released example prompts tested with the Computer Use system:
Prompt 1:
“Go to an online registration form, collect all entries from users based in California, and add their details to a customer dashboard in a separate web portal. Once added, create a follow-up appointment with the assigned specialist for the next available date after 8 a.m., keeping the appointment reason consistent with the user’s original request.”
Prompt 2:
“My art club brainstormed tasks ahead of our fair. The board is messy go to sticky-note-jam.web.app and organize the notes under the right categories. Drag any misplaced notes into their correct sections.”
These prompts highlight the model’s ability to understand context, navigate interfaces, and act safely making it ideal for real operational workflows like data entry, scheduling, or web-based CRM management.
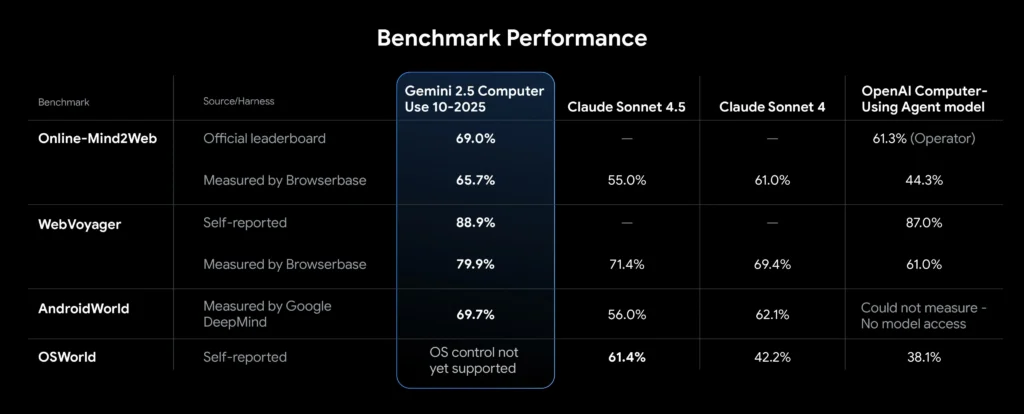
Gemini 2.5 Benchmark Performance and Accuracy Results
Evaluations conducted internally and by independent partners show that Gemini 2.5 Computer Use:
- Leads browser-control performance on Browserbase’s Online-Mind2Web harness.
- Maintains best-in-class latency, outperforming rival models in execution speed.
- Demonstrates consistent accuracy across web and mobile GUI benchmarks.
Detailed results are available in the Gemini 2.5 Computer Use System Card and Browserbase’s published benchmarks.
Gemini 2.5 Safety Architecture and Responsible AI Design
Controlling interfaces autonomously introduces unique risks from unintentional purchases to prompt-injection scams. Google has embedded multi-layered safeguards directly into the model and surrounding systems:
- Per-Step Safety Service
An external inference-time service evaluates every action before execution, preventing potentially harmful or high-impact steps. - System Instructions for Developers
Developers can pre-define which actions must trigger a user confirmation or outright refusal e.g., deleting data, bypassing CAPTCHAs, or altering payment details. - Developer Guidelines & Testing Framework
Comprehensive documentation advises developers on best practices, mandatory testing, and how to integrate additional verification layers.
Together, these measures form one of the industry’s most transparent safety stacks for computer-controlling agents.
Early Gemini Computer Use Testing and Industry Adoption
Before public release, the model was deployed internally and through early-access partners:
- Google’s own teams integrated it for UI testing, reducing test-failure resolution time by over 60%.
- Project Mariner, Firebase Testing Agent, and the AI Mode in Search rely on earlier versions of this model for autonomous interaction testing.
- External developers used it for personal assistants and workflow automation:
- A messaging-based assistant platform reported 50% faster task completion than competing systems.
- An automation startup observed an 18% improvement in complex context parsing for data-entry workflows.
These early outcomes suggest practical readiness for both enterprise QA systems and next-generation personal agents.
How to Get Started with Gemini 2.5 Computer Use Model
Developers can experiment with the Gemini 2.5 Computer Use model today:
- Try it in Browserbase: Run guided demos in a safe sandbox.
- Build locally or in the cloud: Use frameworks like Playwright or deploy via Browserbase VM.
- Access Docs & Community: Full API reference, examples, and a Developer Forum are live on ai.google.dev.
- Enterprise Deployment: Vertex AI offers production integration, scalability, and compliance features for business users.
Why Gemini 2.5 Computer Use Matters for Agentic AI
1. Toward General-Purpose Agents
By enabling models to perceive and act on GUIs, Google edges closer to true agentic AI systems that can perform end-to-end workflows autonomously, beyond text-only reasoning.
2. A Unified Developer Ecosystem
The redesigned AI Studio interface unites model experimentation, code generation, and API deployment, streamlining how developers prototype and ship applications across Google’s AI stack.
3. Competitive Momentum
With OpenAI, Anthropic, and Meta each developing operator-style models, this release ensures Google remains at the forefront of the AI agent race, where speed, reliability, and ecosystem maturity decide adoption.
Looking Ahead
The Gemini 2.5 Computer Use model represents more than a technical upgrade it’s a paradigm shift in how AI interacts with software.
By merging visual reasoning, structured safety, and iterative control, Google has built a foundation for agents that can navigate, learn, and operate digital environments independently.
As the model evolves toward desktop-level capabilities and deeper multimodal integration, the distinction between “AI assistant” and “digital co-worker” will continue to blur.