
Managing social media shouldn’t mean endless copy-paste. Yet most teams still search Twitter (X) for mentions, log posts into spreadsheets, and manually track what’s new. The outcome is predictable: duplicate entries clogging Airtable, messy datasets that are hard to analyze, and wasted hours on work that could be automated. Worse, manual tracking makes it easy to miss trending conversations, leading to lost engagement opportunities.
For social media managers, agencies, and solo creators, the challenge is clear: how do you capture tweets reliably, prevent duplicates in Airtable, and keep your data clean without adding cost or complexity?
Who should use a Twitter (X) to Airtable automation
- Social media managers & community teams tracking brand or keyword conversations.
- Agencies that need low-ops, repeatable monitoring across multiple clients.
- Solo marketers/creators who want no-code/low-code automation that saves time and keeps data clean.
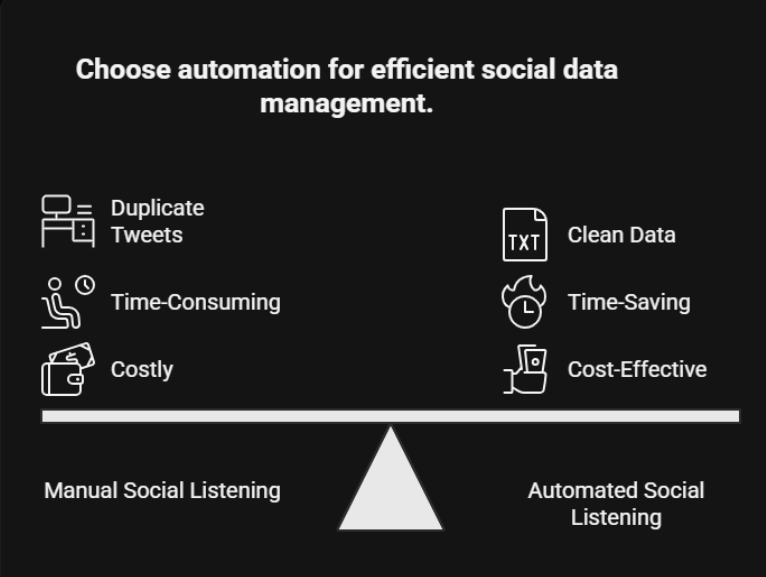
What problems do social teams face when logging Twitter (X) posts manually in Airtable?
Manual social listening creates:
- Duplicate tweets in Airtable.
- Hours wasted on searching, copying, and logging.
- Missed spikes in conversation.
- Messy, unreliable reports.
How does a Twitter to Airtable automation prevent duplicates and keep social data clean
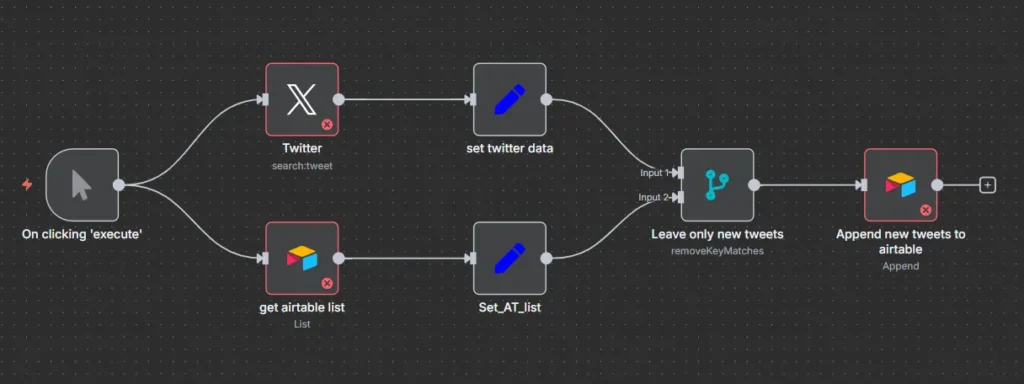
A Twitter to Airtable automation that prevents duplicates and runs on autopilot:Runs fully no-code in n8n, or as an AI-aware workflow with MCP when you want smart classification, summaries, or tagging. Searches Twitter (X) for your keyword (e.g., verstappen). De-duplicates results against existing records by Tweet_id. Appends only new tweets into Airtable with clean fields: Tweet, URL, Author, Time, Likes.
What benefits do social media managers get from automation
- No-code / low-code: n8n canvas; import JSON, wire creds, go.
- Time savings: ~30–60 min/day saved per keyword/brand stream (copy-paste & triage eliminated).
- Cost savings: Replace manual VA hours and avoid heavier SaaS social suites when you just need collection.
- Low operational cost: One small n8n instance + Airtable PAT; optional MCP pieces only when you need AI.
- Efficiency & reliability: Cron schedules, retries, run logs; Airtable remains the single source of truth.
- Easy to understand: Visual nodes, explicit merge/de-dup logic.
- Scalable: Duplicate the flow per keyword/client; add rate limits and alerting as you grow.
- AI-ready (optional): Add MCP to auto-summarize, tag by ICPs, and score relevance.
What’s the best way to build a Twitter to Airtable workflow: n8n or MCP?
Option A: n8n (recommended for most social teams)
- Great for: quick production, lowest ops, no AI reasoning required.
- What you’ll use: Schedule Trigger → X (Twitter) Search → Set (map fields) → Airtable List → Set (map fields) → Merge (keep non-matches by
Tweet_id) → Airtable Append.
Option B: MCP (Model Context Protocol)
- Great for: adding AI steps (e.g., classify by ICPs, summarize to 200 chars, score 0–1) while still calling Twitter/Airtable via tools.
- What you’ll use:
- Twitter MCP server (exposes “search tweets”)
- Airtable MCP server (read/write)
- Scheduler MCP (e.g.,
mcp-cron) to run the prompt every N minutes - An MCP client (Claude Desktop or headless CLI) to host the conversation/tools
What Airtable fields are required for a clean Twitter (X) tracking workflow?
Create a table with these fields (exact names):
Tweet(Long text)Tweet_id(Single line text) unique keyTweet URL(URL)Author(Single line text)Time(Date/Time)Likes(Number)
Tip: Add a View that sorts by Time desc, and another that filters high-engagement tweets (e.g., Likes ≥ 50).
How can you set up a no-code Twitter to Airtable automation in n8n?
Credentials needed
- X / Twitter: your app keys/access token (n8n “X/Twitter” credentials)
- Airtable: a Personal Access Token with access to your base
Importable n8n workflow JSON
Replace the application (base) and table IDs, and select your credential names after import. This runs every 10 minutes.
Field mapping logic (n8n)
Tweet←{{$json["text"]}}Tweet_id←{{$json["id_str"] || $json["id"]}}Tweet URL←https://twitter.com/{{$json["user"]["screen_name"]}}/status/{{$json["id_str"] || $json["id"]}}Author←{{$json["user"]["screen_name"]}}Time←{{$json["created_at"]}}Likes←{{$json["favorite_count"] || 0}}
How can you prevent duplicate Tweet IDs in Airtable using workflow automation?
Merge node → Combine by Matching Fields → Tweet_id vs Tweet_id → Output: Keep Non-Matches.
Only unseen tweets flow to “Airtable (Append)”.
Nice add-ons (still no-code)
- Slack/Discord alert when new rows added (via Slack/Discord nodes).
- Rate-limit guard (Wait/Delay node) if you scale queries.
- Error alerts: On error workflow → email yourself the run URL.
When should social teams use MCP instead of n8n for Twitter to Airtable automation?
When to choose MCP
- You want AI to reason about tweets: summarize, tag by your 8 ICPs, and score relevance before writing to Airtable.
- You want the same capability exposed inside an AI assistant/app (prompt calls tools).
Components you’ll run
- Twitter MCP server (exposes a
search_tweetstool) - Airtable MCP server (list/create/update)
- Scheduler MCP (e.g.,
mcp-cron) to run tasks on a cron - MCP client (Claude Desktop or a headless CLI client)
Minimal config.json (client)
Adjust commands/env to match the servers you prefer. This example shows stdio launch & env placeholders.
Add a scheduled AI task (mcp-cron)
Register a job that runs every 10 minutes and allows tool use:
AI enrichment (optional): Extend the prompt to classify each tweet into your 8 ICPs, assign a relevance score (0–1), and create a short 200-char summary. Write these extra fields to Airtable columns like
ICP_Tags,Relevance,Summary.
How do you map Twitter data into Airtable correctly?
Same as n8n:
Tweet: tweet textTweet_id: tweet idTweet URL:https://twitter.com/{screen_name}/status/{id}Author:user.screen_nameTime:created_atLikes:favorite_count
n8n vs MCP: quick comparison
| Dimension | n8n (no/low-code) | MCP (AI-aware tools) |
|---|---|---|
| Setup speed | ⭐⭐⭐⭐☆ | ⭐⭐☆☆☆ |
| Ops complexity | Low | Medium (servers + client + scheduler) |
| Cost | Low (1 small instance) | Low–Medium (still lightweight) |
| De-dup reliability | Native Merge node | Prompt/tool logic (reliable with tests) |
| Scheduling | Built-in Cron | Add mcp-cron (or similar) |
| Logs/Retries | Native | Depends on client/scheduler |
| AI reasoning | External step | Built-in to the flow |
| Team handoff | Very easy | Requires MCP familiarity |
Recommendation: Start with n8n for ingestion. Add MCP enrichment later if/when you need AI-driven tagging/scoring.
What time and cost savings can social teams expect from Twitter to Airtable automation?
- Time saved: If you tracked one keyword manually for 30 min/day → ~10 hours/month saved.
- Cost avoided: At $10–$20/hr VA rate → $100–$200/month per stream saved.
- Coverage: 100% capture of new tweets matching your query (with de-dup).
- Quality: With MCP enrichment, expect faster triage (top tweets bubble up by score).
What should you do if duplicates still slip into Airtable or tweets don’t appear?
- No rows appear: Confirm the Schedule Trigger is activated and time zone matches your expectation.
- Duplicates still slip in: Check both inputs into the Merge node; ensure both sides map
Tweet_idas strings. Turn on fuzzyCompare. - Rate limits / API errors: Add a Wait node between runs or reduce
limitto 50. - Airtable list too large: Add date filters or use a View to scope recent records.
- MCP task not running: Verify the cron format (seconds included), tool discovery in the client, and that credentials are present in env.
How do you keep API keys and Airtable tokens secure in this workflow?
- Keep API keys in credential vaults / env vars; never hardcode in JSON.
- In Airtable, restrict PAT scope to the target base.
- For agencies, isolate each client into a separate base and n8n workflow copy.
How can you extend this workflow with Slack alerts, campaigns, or multi-keyword tracking?
- Alerts: Post to Slack/Discord when new rows are added (include top 3 Likes).
- Campaign routing: If tweet includes your campaign hashtag, tag and push to a Notion or Jira board.
- Auto-responses (careful!): Queue drafts in a “Review” view, human approves before posting.
- Multi-keyword: Duplicate the flow per topic (
verstappen,brand,competitor, etc.). - Search variants: Run “recent” vs “popular” result types in parallel and label them.
FAQ
A: Use automation (like n8n or MCP) to compare Tweet_id with existing Airtable records before appending. This ensures only new tweets are saved, preventing duplicates.
A: Yes. Airtable offers extensions and filters to find duplicates by Tweet_id. But the best approach is to stop them upfront with an automated Twitter → Airtable workflow.
A: Not natively. Airtable can flag duplicates with extensions, but it won’t block them by default. That’s why workflows like this use the Tweet_id as a unique key to filter duplicates at the source.
A: By using no-code automation tools (n8n, MCP, Zapier alternatives) that always check for existing Tweet IDs before saving new ones, keeping the dataset clean.
A: Normalize your incoming data (Tweet, URL, Author, Time, Likes) and enforce uniqueness via Tweet IDs. That way, every record in Airtable represents a distinct tweet.
A: Use Tweet_id as the column that acts like a “primary key.” Automation ensures no duplicate Tweet IDs are inserted into Airtable.
A: After the fact, you can group by Tweet_id and remove duplicates manually. But for social media workflows, it’s better to prevent them during import with n8n/MCP.
A: Unlike databases, Airtable doesn’t enforce constraints. The “constraint” here is workflow logic: the Merge node (in n8n) or prompt logic (in MCP) filters duplicates by Tweet ID.
A: Set up a scheduled, de-duped pipeline where tweets are compared against Airtable’s existing dataset before being saved. This keeps Airtable clean and analysis-ready.


